Content quality
The quality of the content published on your site is a legal and editorial issue.
We guarantee calm, interesting and readable discussions.
The arguments published are of good quality and those put forward are the best worked.
It works as follows:
-
The posted arguments are sent to the moderation manager (the Logora team, in the vast majority of cases).
They are moderated a priori. 80% to 85% of arguments are processed automatically, i.e. instantly. 15% to 20% of arguments are processed manually, every 24 hours. -
The arguments validated by the moderation are published. Our relevance algorithm rates each contribution and highlights those that appear to be the most well thought out.
How moderation works
Moderation management is offered by Logora (recommended solution), it can also be handled by your moderation providers.
The moderation process is as follows: we have built a moderation algorithm by labelling over 45,000 contributions.
The algorithm automatically accepts arguments that are considered readable, well-written and non-hateful. When the algorithm is not sure of the quality of the argument (unknown source, new turns of phrase, new concepts), the argument is sent to a member of our team for manual moderation.
This concerns 15 to 20% of the arguments. We perform moderation every 24 hours on weekdays. Pending posts are seen as published by their authors to make their experience more fluid.
All of our moderators are native speakers and have a university degree.
We have processed over two million arguments for all of our partners with a 100% success rate of detecting hateful, unreadable and illegal messages.
Our moderation interface is visible from your administration area. Our work is transparent and you have the possibility to intervene (accept/reject contributions) if you wish.
On this example, you can see a list of arguments passed by the moderation algorithm: some are automatically accepted, others rejected and pending.
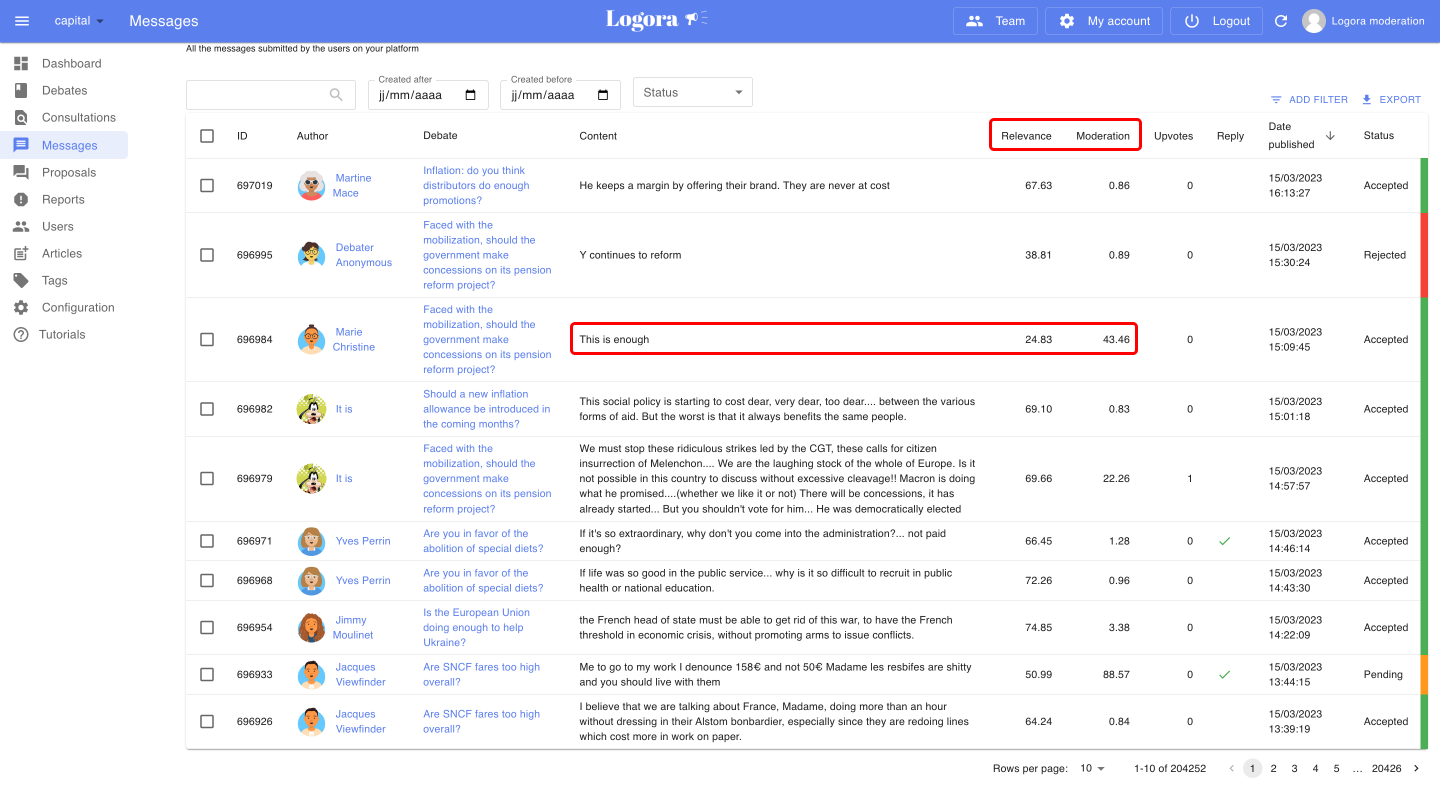
A low moderation score means that the algorithm considers the argument to be safe: several such arguments have been accepted in the past, it may accept it automatically. A high moderation score means that this kind of argument is unknown or has been rejected in the past. In this case, the argument is put on hold for human review.
To learn more about setting up moderation, read our documentation article in Configuration > Moderation.
How the argument prioritisation works
We have created a 'relevance' algorithm that highlights the best-written arguments.
The aim is to make your contribution space as interesting as possible and to reward the most committed participants.
The relevance algorithm is independent of the moderation algorithm.
The question we're asking is this: once the arguments are in good order (after moderation), how do you choose which ones deserve to be highlighted? Our role is not to judge the substance of the arguments, so we focus on their form and structure to distinguish them.
The algorithm calculates the quality of the text. Four important indicators are taken into account:
- Text length
- Percentage of capital letters
- Percentage of punctuation characters
- Percentage of grammatical or spelling errors
This last indicator uses the Open Source LanguageTool library (https://languagetool.org) to calculate the number of errors in a text. Example: "Hello, here's a teexte test" contains three errors, one each for punctuation, grammar and spelling.
The number of votes is not taken into account as an indicator in our model. The aim is to calculate the pure quality of the text. The vote will be added to the score afterwards and will have an influence on the final score, but is not included in our model.
The final score is calculated as follows: S(x,y) = x + (y/100)^1.1 * (1 - x), where x is the quality score and y is the number of votes.
When a user publishes an argument, the model predicts a score between 0 and 100.
This operation is fully automated, although the score of an argument can be modified a posteriori from your administration space.
We have carried out thousands of annotations on different types of content, making a significant contribution to the development of the algorithm. The average of our annotations was used to run a regression and find an appropriate function to calculate the score. A random forest model was then trained on the annotations. This model corresponds as closely as possible to our vision of the relevance score.
Between two well written, developed and sourced arguments, it is difficult to judge that one argument is more interesting than another. However, this feature allows the best written arguments to be rewarded by distinguishing them from shorter and less constructed arguments.